JSON은 JavaScript Object Notation라는 의미의 축약어로 데이터를 저장하거나 전송할 때 많이 사용되는 경량의 DATA 교환 형식이다. JSON 표현식은 사람과 기계 모두 이해하기 쉬우며 용량이 작아서, 최근에는 JSON이 XML을 대체해서 데이터 전송 등에 많이 사용된다. JSON은 데이터 포맷일 뿐이며 어떠한 통신 방법도, 프로그래밍 문법도 아닌 단순히 데이터를 표시하는 표현 방법이다.
JSON 특징
1. JSON은 자바스크립트를 확장하여 만들어짐
2. JSON은 자바스크립트 객체 표기법을 따름
3. JSON은 사람과 기계가 모두 읽기 편하도록 고안됨
4. JSON은 프로그래밍 언어와 운영체제에 독립적
JSON 자료형
Number
JavaScript에서 배정되는 정밀한 부동 소수점 형식
String
큰 따옴표를 사용한 유니코드
Boolean
true 또는 false
Array
연속된 값들의 정렬
Value
string, number, true 또는 false, null 등
Object
정렬되지 않은 key:value 콜렉션
Whitespace
토큰쌍 사이에서 사용 가능
null
비었음
JSON의 문제점
AJAX 는 단순히 데이터만이 아니라 JavaScript 그 자체도 전달할 수 있다. 이 말은 JSON데이터라고 해서 받았는데 단순 데이터가 아니라 JavaScript가 될 수도 있고, 그게 실행 될 수 있다는 것이다. (데이터인 줄 알고 받았는데 악성 스크립트가 될 수 있다.)
위와 같은 이유로 받은 내용에서 순수하게 데이터만 추출하기 위한 JSON 관련 라이브러리를 따로 사용하기도 한다.
REST(Representational State Transfer)의 약자로자원을 이름으로 구분하여 해당 자원의 상태를 주고받는 모든 것을 의미합니다.
즉 REST란
HTTP URI(Uniform Resource Identifier)를 통해 자원(Resource)을 명시하고,
HTTP Method(POST, GET, PUT, DELETE)를 통해
해당 자원(URI)에 대한 CRUD Operation을 적용하는 것을 의미합니다.
CRUD Operation이란 CRUD는 대부분의 컴퓨터 소프트웨어가 가지는 기본적인 데이터 처리 기능인 Create(생성), Read(읽기), Update(갱신), Delete(삭제)를 묶어서 일컫는 말로 REST에서의 CRUD Operation 동작 예시는 다음과 같다.
Create : 데이터 생성(POST) Read : 데이터 조회(GET) Update : 데이터 수정(PUT) Delete : 데이터 삭제(DELETE)
REST 구성 요소
REST는 다음과 같은 3가지로 구성이 되어있다.
자원(Resource) : HTTP URI
자원에 대한 행위(Verb) : HTTP Method
자원에 대한 행위의 내용 (Representations) : HTTP Message Pay Load
REST의 특징
Uniform (유니폼 인터페이스) : HTTP 표준에만 따른다면,안드로이드/IOS 플랫폼이든, 특정 언어나 기술에 종속되지 않고 모든 플랫폼에 사용할 수 있으며, URI로 지정한 리소스에 대한 조작이 가능한 아키텍처 스타일을 의미한다.
Stateless (무상태성) : REST는 무상태성 성격을 가진다. 다시 말해 작업을 위한 상태정보를 따로 저장하고 관리하지 않는다. 세션 정보나 쿠키 정보를 별도로 저장하고 관리하지 않기 때문에API서버는 들어오는 요청만을 단순히 처리하면 된다. 그래서 서비스의 자유도가 높아지고 서버에서 불필요한 정보를 관리하지 않음으로써 구현이 단순해진다.
Cacheable (캐시 가능) : REST의 가장 큰 특징 중 하나는 HTTP라는 기존 웹 표준을 그대로 사용하기 때문에, 웹에서 사용하는 기존 인프라를 그대로 활용할 수 있다. 따라서 HTTP가 가진 캐싱 기능이 적용할 수 있다. HTTP 프로토콜 표준에서 사용하는 Last-Modified 태그나 E-Tag를 이용하면 캐싱 구현이 가능하다.
Self-descriptiveness (자체 표현 구조) : REST의 또 다른 큰 특징 중 하나는 REST API 메시지만 보고도 이를 쉽게 이해할 수 있는 자체 표현 구조로 되어 있다는 것이다.
Client - Server 구조 : REST 서버는 API 제공, 클라이언트는 사용자 인증이나 컨텍스트(세션, 로그인 정보) 등을 직접 관리하는 구조로 각각의 역할이 확실히 구분되기 때문에 클라이언트와 서버에서 개발해야 할 내용이 명확해지고 서로 간 의존성이 줄어들게 된다.
계층형 구조 : REST 서버는 다중 계층으로 구성될 수 있으며 보안, 로드 밸런싱, 암호화 계층을 추가해 구조상의 유연성을 둘 수 있고 PROXY, 게이트웨이 같은 네트워크 기반의 중간매체를 사용할 수 있게 한다.
REST의 장단점
장점
HTTP 프로토콜의 인프라를 그대로 사용하므로 REST API 사용을 위한 별도의 인프라를 구출할 필요가 없다.
HTTP 프로토콜의 표준을 최대한 활용하여 여러 추가적인 장점을 함께 가져갈 수 있게 해 준다.
HTTP 표준 프로토콜에 따르는 모든 플랫폼에서 사용이 가능하다.
Hypermedia API의 기본을 충실히 지키면서 범용성을 보장한다.
REST API 메시지가 의도하는 바를 명확하게 나타내므로 의도하는 바를 쉽게 파악할 수 있다.
여러 가지 서비스 디자인에서 생길 수 있는 문제를 최소화한다.
서버와 클라이언트의 역할을 명확하게 분리한다.
단점
표준이 자체가 존재하지 않아 정의가 필요하다.
사용할 수 있는 메소드가 4가지밖에 없다.
HTTP Method 형태가 제한적이다.
브라우저를 통해 테스트할 일이 많은 서비스라면 쉽게 고칠 수 있는 URL보다 Header 정보의 값을 처리해야 하므로 전문성이 요구된다.
MySQL은 구조화된 쿼리 언어(SQL)를 기반으로 하는 무료 오픈 소스 관계형 데이터베이스 관리 시스템(RDBMS)이며 웹사이트 및 애플리케이션을 위한 기본 관계형 데이터 스토리지 솔루션이다.
MySQL은 사용하기 쉽고 빠르고 안정적이기 때문에 웹 애플리케이션에 널리 사용되는 RDBMS이다. 또한 이 소프트웨어에는 대규모 사용자 커뮤니티가 있으며 많은 상업적 지원 옵션을 사용할 수 있습니다. MySQL은 또한 데이터를 다양한 형식으로 저장하고 고유한 스키마를 정의할 수 있도록 하여 뛰어난 유연성을 제공한다.
MySQL을 사용하는 이유는 무엇입니까?
MySQL은 데이터를 저장하는 데이터베이스이다. 소규모 웹사이트에서 대기업에 이르기까지 무엇이든 사용할 수 있다. MySQL은 빠르고 안정적이며 사용하기 쉽기 때문에 인기가 있다. 또한 필요에 맞게 사용자 정의할 수 있는 많은 기능이 있다.
MySQL의 가장 일반적인 용도는 다음과 같다.
웹사이트용 데이터 저장
모바일 앱용 데이터 저장
기업 애플리케이션용 데이터 저장
고객 또는 클라이언트의 데이터베이스 생성
의료 정보 저장
금융 정보를 저장.
MySQL의 장점 중 일부는 다음과 같다.
무료이며 오픈 소스이며 신뢰할 수 있다.
ACID 속성을 사용하여 트랜잭션 무결성 제공
InnoDB 및 MyISAM을 포함한 여러 스토리지 엔진 지원
지리적으로 분산된 시스템에 대한 복제 지원
많은 정보를 사용할 수 있는 대규모 사용자 커뮤니티.
MySQL의 단점?
결론적으로 MySQL은 강력하고 확립된 오픈 소스 관계형 데이터베이스 관리 시스템이지만 사용 시 몇 가지 단점이 있다. MySQL은 Oracle Database 및 Microsoft SQL Server와 같은 다른 데이터베이스보다 유연성이 떨어집니다. 즉, 프로젝트에 향후에도 계속 적응할 수 있도록 하려면 개발자 스스로 더 많은 작업을 수행해야 할 수 있습니다.
git은 형상 관리 또는 버전 관리를 위해 사용하는 시스템이다. 어떤 파일 또는 시스템을 개발할 때, 해당 파일 또는 시스템에 대한 개발 상황을 버전별로 기록할 때 사용한다. git을 통해 버전을 관리하면서 필요할 때 과거의 버전으로 돌아가 코드를 수정하거나 가져올 수 있다.
untracked : 새로 만들어진 파일, 기존에 존재하던 프로젝트에서 깃을 초기화하여 아직 트래킹 하지 않은 파일
traked : 깃이 이미 알고있고, 트래킹 하고 있는 파일
traked에서도 두가지 구분이 가능하다
트래킹 하고 있는 시점에서 수정(이전 버전과 비교)이 되었는지 안되었는지에 따라
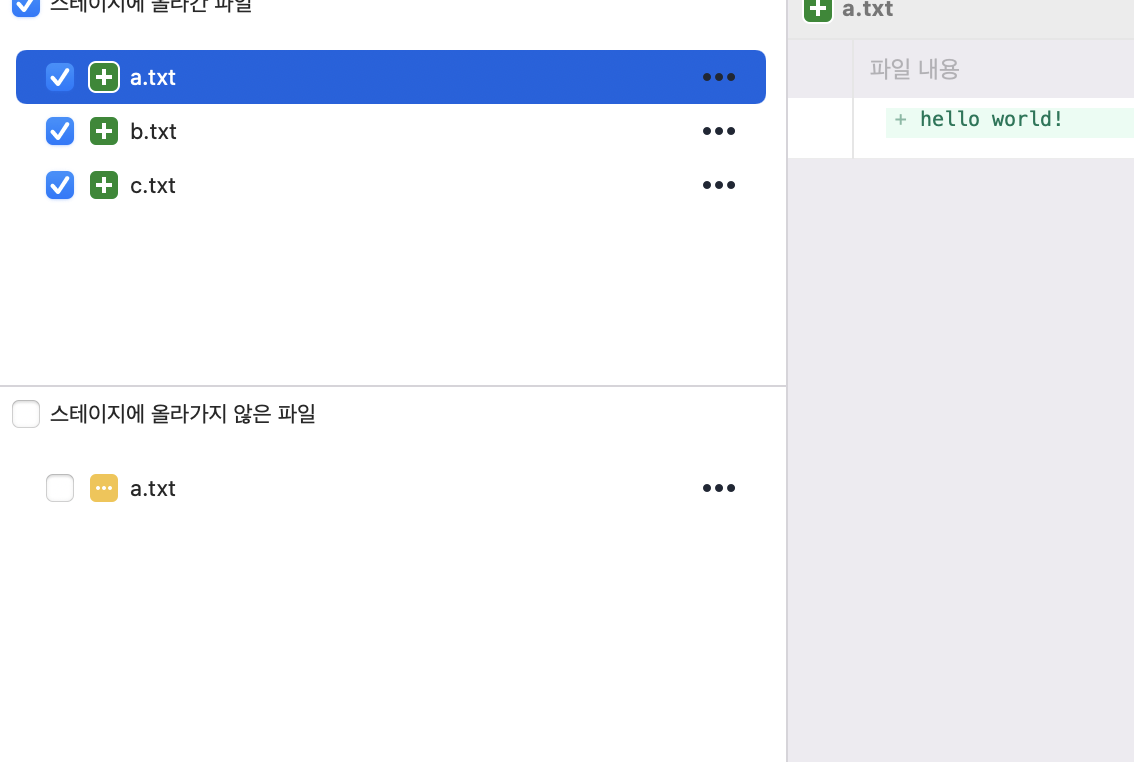
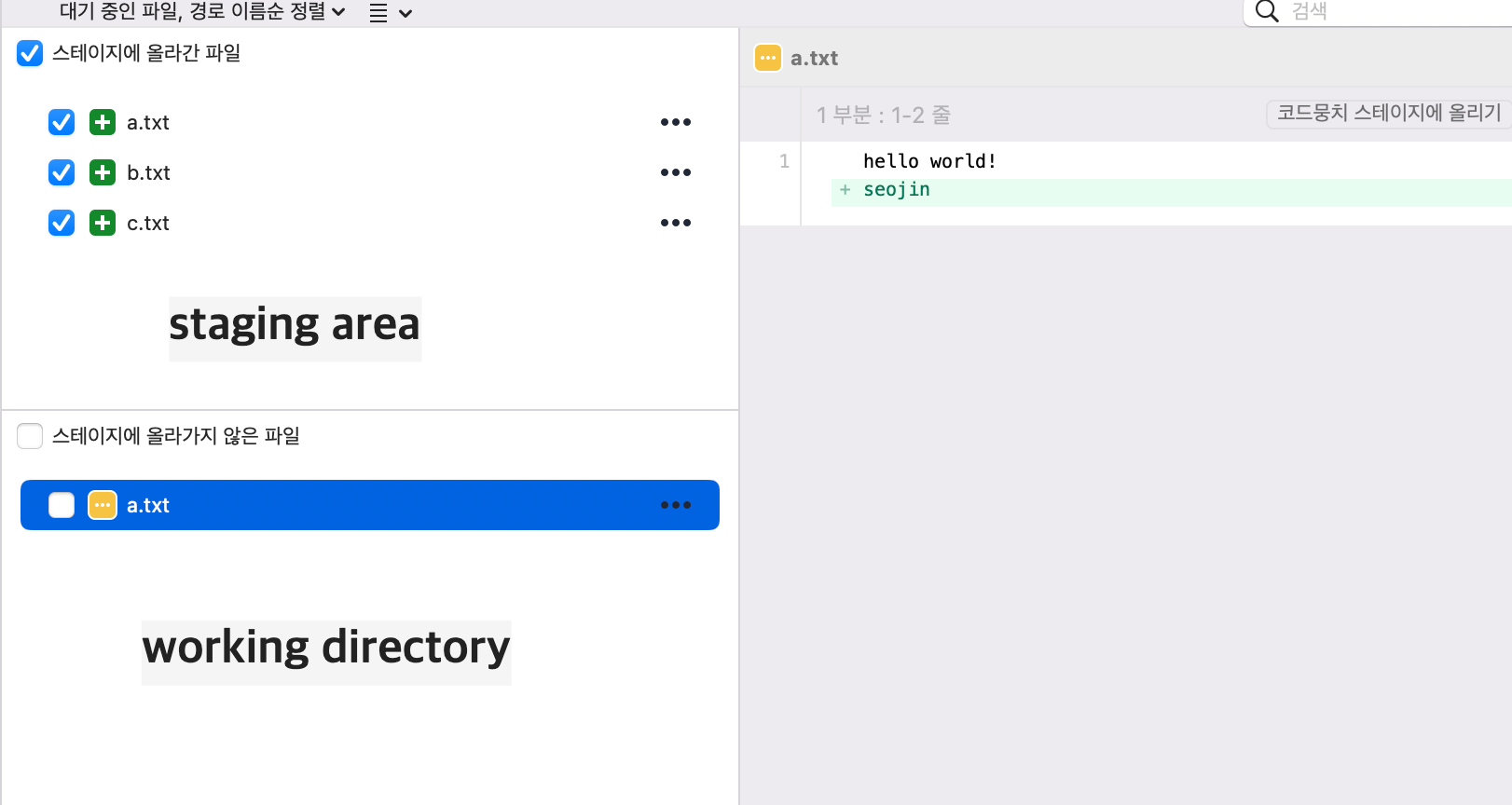
unmodified , modified 라고 한다. 이 중에서 수정이 된 modified에 속한 파일만 staging area로 이동이 가능하다.
정리하자면 working directory에서 staging area로 넘겨준 파일을 다시 한번 수정하였을 때
수정한 파일은 working directoty 중 tracked, 그 중에서도 modified 파일이다.
위 사진처럼 a파일에서 추가한 seojin은 staging area에 추가된것이 아니기 때문에 동일한 파일이여도 staging이 된 이후에 수정된 내용은 다시 working directory에 올라온다.
비유가 적절치 못할 수 도 있지만 예를 들어보자면 블로그에 글을 게시한 상태라고 가정 하자.
그 글을 수정하는동안 글이 사라지지 않고 블로그에 게시가 그대로 되어 있는것처럼 staging area에 남아있는 것이다. 이 글을 임시저장을 한다면 working directory에 남아 있는것이고 글을 다시 게시하면 staging area에 업데이트된 버전의 글이 적용되어 올라가는것이다.
위와 같은 workflow는 내 컴퓨터에서만 즉 local에서만 저장되기에 (local)컴퓨터에 이상이 생기면 작업에 문제가 생길 수 있다.
그렇기에 깃허브와 같은 분산서버 시스템에 나의 디렉토리를 저장할 필요가 있다.
commit? push?
깃허브나 깃을 사용할 때 사용하는 명령어들을 아무 생각없이 사용했던 경험이 있다.
간단하게나마 요약해보자
add : working directory -> staging area로 넘겨줄 때 사용
add * : -> 모든 파일을 staging area로 넘겨줌
commit : staging area -> .git directory로 넘겨줄 때 사용
checkout : .git directory -> working directory로 넘겨줄 때 사용
push : github와 같은 서버에 나의 .git directory를 업로드 할 때 사용
pull : 서버에서 다시 로컬로 다운 받을 때 사용
rm --cached * : 모든 파일을 staging area에서 제거 -> untracked 상태가 된다.
엔터프라이즈 자바빈즈(Enterprise JavaBeans;EJB)는 기업환경의 시스템을 구현하기 위한서버측컴포넌트모델이다. 즉, EJB는 애플리케이션의 업무 로직을 가지고 있는 서버 애플리케이션이다. EJB 사양은Java EE의자바 API중 하나로, 주로 웹 시스템에서JSP는 화면 로직을 처리하고, EJB는 업무 로직을 처리하는 역할을 한다. (출처 : 위키백과)
이러한 EJB의 문제점으로는 비지니스 로직에 특정 기술이 종속된다는 점이다.
이러한 문제점들을 보완하고 등장한 스프링은 특정 기술에 종속되지 않고 객체를 관리할 수 있는 컨테이너를 제공하는 것이 스프링의 기본철학이다.
}
스프링은 자바 진영의 웹 프레임 워크이다.
다음은 자바를 이용한 객체지향 프로그래밍의 핵심 개념들이다.
1. 캡슐화2. 상속3. 추상화4. 다형성
SOLID - 좋은 객체 지향 설계의 5가지 원칙
SRP: 단일 책임 원칙(single responsibility principle)
한 클래스는 하나의 책임만 가져야 한다.
OCP: 개방-폐쇄 원칙 (Open/closed principle)
확장에는 열려 있으나 변경에는 닫혀 있어야 한다.
기능을 추가하려면 소스코드의 수정이 불가피하다. 다형성을 이용하더라도 클라이언트 코드를 변경해야 한다. 이는 OCP 원칙에 위배되는 것이다. 이것을 해결하기 위해서는 객체를 생성하고, 연관관계를 맺어주는 별도의 조립, 설정자가 필요하다.
LSP: 리스코프 치환 원칙 (Liskov substitution principle)
프로그램의 객체는 프로그램의 정확성을 깨뜨리지 않으면서 하위 타입의 인스턴스로 바꿀 수 있어야 한다.
다형성에서 하위 클래스는 인터페이스 규약을 다 지켜야 한다는 것, 다형성을 지원하기 위 한 원칙, 인터페이스를 구현한 구현체는 믿고 사용하려면, 이 원칙이 필요하다.
ISP: 인터페이스 분리 원칙 (Interface segregation principle)
특정 클라이언트를 위한 인터페이스 여러 개가 범용 인터페이스 하나보다 낫다.
DIP: 의존관계 역전 원칙 (Dependency inversion principle)
프로그래머는 “추상화에 의존해야지, 구체화에 의존하면 안된다.” 의존성 주입은 이 원칙 을 따르는 방법 중 하나다. 쉽게 이야기해서 구현 클래스에 의존하지 말고, 인터페이스에 의존하라는 뜻이다.
순수 자바 코드를 활용하여 이러한 규칙들을 따라가 보면 스프링의 핵심원리들에 도달하게 된다.
스프링 특징
① "경량 컨테이너"(크기와 부하의 측면)로서 자바 객체를 직접 관리
- 각각의 객체 생성, 소멸과 같은 라이프 사이클을 관리하며 스프링으로부터 필요한 객체를 얻어올 수 있다.
② 제어 역행(IoC : Inversion of Control) - 애플리케이션의 느슨한 결합을 도모. - 컨트롤의 제어권이 사용자가 아니라 프레임워크에 있어 필요에 따라 스프링에서 사용자의 코드를 호출한다. 개발자가 직접 제어해야 하는 부분들을 컨테이너가 대신 처리하는 것, 제어의 주도권이 개발자 -> 스프링 프레임워크로 넘어가짐
③ 의존성 주입(DI : Dependency Injection) - 각각의 계층이나 서비스들 간에 의존성이 존재할 경우 프레임워크가 서로 연결시켜준다.
③ 관점지향 프로그래밍(AOP : Aspect-Oriented Programming) - 트랜잭션이나 로깅, 보안과 같이 여러 모듈에서 공통적으로 사용하는 기능의 경우 해당 기능을 분리하여 관리할 수 있다.
④ 애플리케이션 객체의 생명 주기와 설정을 포함하고 관리한다는 점에서 일종의 "컨테이너"(Container)라고 할 수 있다. - iBatis, myBatis나 Hibernate 등 완성도가 높은 데이터베이스 처리 라이브러리와 연결할 수 있는 인터페이스를 제공한다.
⑤ 트랜잭션 관리 프레임워크 - 추상화된 트랜잭션 관리를 지원하며 설정 파일(xml, java, property 등)을 이용한 선언적인 방식 및 프로그래밍을 통한 방식을 모두 지원한다.
⑥ 모델-뷰-컨트롤러 패턴 - 웹 프로그래밍 개발 시 거의 표준적인 방식인 "Spring MVC"라 불리는 모델-뷰-컨트롤러(MVC) 패턴을 사용한다. - DispatcherServlet이 Controller 역할을 담당하여 각종 요청을 적절한 서비스에 분산시켜주며 이를 각 서비스들이 처리를 하여 결과를 생성하고 그 결과는 다양한 형식의 View 서비스들로 화면에 표시될 수 있다.
⑦ 배치 프레임워크 - 스프링은 특정 시간대에 실행하거나 대용량의 자료를 처리하는데 쓰이는 일괄 처리(Batch Processing)를 지원하는 배치 프레임워크를 제공한다. 기본적으로 스프링 배치는 Quartz 기반으로 동작한다.